Isso conta todas as linhas da tabela venda, dando-nos o número total de vendas. Simples, não?

Somando Valores com SUM
Agora, imagine querer calcular o total de receitas geradas. A função SUM soma valores, o que é perfeito para isso. Ao somar os valores de todas as vendas, podemos ter uma ideia do desempenho financeiro:
Este comando nos dá a receita total, multiplicando a quantidade de itens vendidos pelo valor unitário e somando tudo.

A Média com AVG
E sobre o ticket médio das vendas? AVG vem ao resgate, calculando a média de um conjunto de valores. Isso nos ajuda a entender o valor médio de uma venda:

Encontrando Extremos com MIN e MAX

Às vezes, queremos identificar nossos melhores e piores dias de vendas. As funções MIN e MAX são perfeitas para isso, encontrando os valores mínimo e máximo em um conjunto de dados, respectivamente:
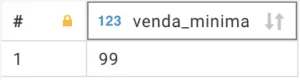

Erros Comuns e Soluções ao Usar Funções de Agregação
As funções de agregação no SQL, incluindo COUNT, SUM, AVG, MIN e MAX, são ferramentas poderosas para análise de dados, mas seu uso incorreto pode levar a resultados não confiáveis ou a um desempenho de consulta subótimo. Vamos explorar alguns dos erros mais comuns e como solucioná-los para otimizar suas operações de banco de dados.
Erro 1: Desempenho Reduzido em Grandes Conjuntos de Dados
Problema: Consultas que utilizam funções de agregação em tabelas muito grandes podem ser extremamente lentas. Solução: Implemente índices nos campos usados nas funções de agregação e nos critérios de JOIN e WHERE. Os índices ajudam o banco de dados a encontrar rapidamente os dados necessários sem escanear toda a tabela.
Erro 2: Resultados Imprecisos com Funções de Soma e Média
Problema: SUM e AVG podem produzir resultados imprecisos quando aplicados a campos com tipos de dados inadequados, como floating point. Solução: Use tipos de dados numéricos precisos, como DECIMAL, para colunas envolvidas em cálculos monetários ou outras medidas críticas.
Erro 3: Uso Incorreto de GROUP BY
Problema: A agregação de dados sem um entendimento adequado de GROUP BY pode levar a agregações incorretas ou incompletas. Solução: Certifique-se de incluir na cláusula GROUP BY todos os campos não agregados presentes na seleção. Isso garante que cada grupo único seja corretamente formado antes da agregação.
Erro 4: Ignorar Nulls em Agregações
Problema: Funções como SUM e AVG ignoram valores NULL, o que pode levar a interpretações erradas dos resultados. Solução: Antes de aplicar funções de agregação, considere a utilização de COALESCE para substituir valores NULL por zeros ou outro valor significativo, garantindo a integridade dos cálculos.
Erro 5: Performance de JOIN em Consultas Agregadas
Problema: JOIN mal projetados podem desacelerar significativamente consultas que incluem funções de agregação. Solução: Revise as condições de JOIN para garantir que são necessárias e eficientes. Utilize estratégias como INNER JOIN para limitar as linhas antes da agregação, reduzindo o overhead.
Incorporar essas soluções em seu trabalho com SQL não só aumentará a eficiência e a precisão de suas consultas, mas também ajudará a evitar armadilhas comuns que podem comprometer seus projetos de análise de dados.
Consolidando o Impacto das Funções de Agregação em SQL na Análise de Dados
Dominar as funções de agregação em SQL transforma radicalmente sua capacidade de analisar dados complexos, oferecendo insights práticos e estratégicos essenciais para qualquer analista de dados. Este guia não apenas equipa você com o conhecimento teórico necessário, mas também destaca técnicas práticas que permitem a aplicação eficaz dessas funções no mundo real.
Não limite sua jornada de aprendizado a este artigo! Continue explorando e expandindo suas habilidades em SQL com recursos adicionais e aplicações práticas. Encorajamos você a visitar a documentação oficial do PostgreSQL para aprofundar seu entendimento sobre as nuances das funções de agregação e suas potenciais aplicações.
Mergulhe nos fundamentos essenciais de SQL com nosso guia completo, perfeito para quem deseja iniciar uma carreira em ciência de dados. Em Fundamentos de SQL para Análise de Dados, exploramos como o domínio do SQL constrói uma base sólida e oferece vantagens significativas na análise de dados.
Tem dúvidas ou deseja compartilhar como aplicou esses conhecimentos? Deixe seu comentário abaixo ou entre em contato conosco. Sua jornada em ciência de dados é importante para nós, e estamos aqui para apoiar seu sucesso continuado. Continue explorando, questionando e, acima de tudo, descobrindo!