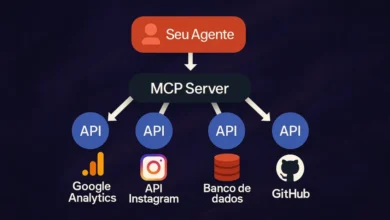
Bem-vindo ao mundo do SQL, uma ferramenta indispensável na caixa de ferramentas de qualquer cientista de dados. Para iniciar com sucesso uma carreira em ciência de dados, é crucial dominar os fundamentos de SQL para análise de dados. Dominar banco de dados não apenas constrói uma base sólida, mas também oferece uma vantagem significativa na análise de dados. A familiaridade com sistemas de gerenciamento de banco de dados, juntamente com um entendimento profundo sobre a estruturação, armazenamento e acesso aos dados, são pilares essenciais nesse contexto.
Entender conceitos chave, incluindo tabelas, relações, e chaves primárias e secundárias, além de normalização e índices, clareia e expande sua visão sobre a organização dos dados em um banco de dados. Essa perspectiva é indispensável para a realização de consultas precisas e eficientes, permitindo a extração de dados relevantes para análises subsequentes.
Neste post, exploraremos os 7 Fundamentos Essenciais de SQL para Análise de Dados:
- Os conceitos fundamentais de bancos de dados e tabelas
- Os comandos SQL fundamentais
- Filtrar dados com WHERE
- Expandir análises com JOIN
- Consultas avançadas e junções SQL
- Funções de agregação e GROUP BY
- Otimização de consultas
Cada seção deste post irá equipá-lo com as competências necessárias para manipular e aproveitar ao máximo o potencial dos dados, preparando-o para enfrentar desafios analíticos mais complexos e tirar maior proveito dos dados à sua disposição.

No meu dia a dia, vejo que dominar os comandos básicos de SQL, como SELECT, FROM, WHERE, JOIN e GROUP BY, fundamenta as tarefas mais complexas em análise de dados. Por exemplo, o agrupamento de dados é uma operação crucial para sumarizar informações e identificar padrões ou tendências.
Além disso, estou ciente de que a eficiência na escrita de consultas impacta diretamente a performance e a velocidade de acesso aos dados. Por isso, dedico tempo para otimizar minhas consultas e selecionar as melhores estratégias para extrair os dados necessários. Essas habilidades são cruciais em um campo onde o volume de dados é cada vez maior e mais complexo.
Prepare-se para uma jornada educativa que está moldando o futuro da análise de dados!
Conteúdo
Conceitos Básicos de SQL
Antes de avançar na análise de dados com SQL, é fundamental compreender seus pilares. Dominar estes conceitos é o primeiro passo para manipular bancos de dados eficientemente.
Banco de Dados e Tabelas
Muitas pessoas usam planilhas do Excel para organizar e gerenciar dados, graças à sua interface intuitiva que organiza informações em linhas e colunas. Contudo, além das planilhas, existe o mundo dos bancos de dados, que oferece uma abordagem mais robusta e sistemática para a manipulação de dados.
Num banco de dados, as informações são armazenadas em estruturas chamadas tabelas, que são semelhantes às planilhas do Excel na aparência, com dados organizados em linhas (registros) e colunas (atributos). Cada linha em uma tabela de banco de dados representa um registro único, como um cliente ou uma transação, e cada coluna representa uma propriedade desse registro, como nome, email ou data.
A principal diferença entre o Excel e um banco de dados é como os dados são gerenciados e inter-relacionados. Enquanto o Excel é ótimo para análises e cálculos rápidos em volumes menores de dados, bancos de dados são projetados para lidar com grandes volumes de dados, oferecendo recursos avançados como a definição de relações entre diferentes conjuntos de dados (tabelas), garantindo a integridade e a segurança dos dados, e permitindo consultas complexas com a linguagem SQL.
Explorando os Comandos SQL para Análise de Dados Eficiente
Na jornada para se tornar um especialista em ciência de dados, o domínio dos comandos SQL é um diferencial que não pode ser subestimado. Compreender e aplicar os comandos SQL para análise de dados não só agiliza o processo de consulta, como também eleva a qualidade das insights extraídos.
SELECT e FROM: Os Alicerces da Consulta
No coração de qualquer análise de dados com SQL está o comando SELECT, utilizado para especificar quais colunas de dados você deseja visualizar, e o FROM, que indica de qual tabela esses dados serão extraídos. A estrutura básica de uma consulta SQL começa com: